GLM-4.6 Launch Test: How Does It Compare to Claude 4.5?
GLM-4.6 was quietly released last night, and we immediately conducted a 48-hour blind test against Claude 4.5. The results were surprising: GLM led by 9.4% in Chinese instruction adherence, surpassed Claude by 7% in code execution success rate, and scored 142 points on the 2024 college entrance mathematics exam, 18 points higher than Claude. However, in multi-turn logical reasoning and long-context recall, Claude maintained its reputation as the most human-like model. Which model better understands Chinese developers? Which is more suitable for production environments? Today, we present six sets of test screenshots and prompts for you to easily discern where to allocate your computational resources.

Key Highlights
- GLM-4.6 launched with improved rankings while maintaining the same pricing, aligning its performance with Claude 4 and surpassing other domestic models.
- The GLM developer subscription has been upgraded, offering 1/7 the price of Claude 4 with 9/10 effectiveness, making it a worthy choice.
This National Day, the AI community is buzzing with activity, with Deepseek-V3.2 open-sourcing and Claude Sonnet 4.5 making surprise appearances, as leading AI companies showcase their strengths.
In this competitive landscape, Zhizhu released the new GLM-4.6, which is the strongest coding model to date.
Two months ago, I strongly recommended GLM-4.5 in my in-depth review, believing it to be the best domestic coding model at that time in terms of quality, cost, and speed. As a result, Zhizhu’s model invocation revenue on Openrouter surged past the combined revenue of other domestic models.
This time, GLM-4.6 brings even more enhancements:
This article will provide valuable reference information regarding model details, test results (directly comparing Claude 4.5 and Deepseek V3.2), pricing, and comprehensive conclusions.
GLM Model: Features Overview
Zhizhu has released only one model this time:
- GLM-4.6, Large Version, 355B-A32B.
It has made comprehensive improvements in real programming, context length, token efficiency, reasoning ability, and agent tasks.
Here’s a summary of the official introduction for quick understanding of the new features:
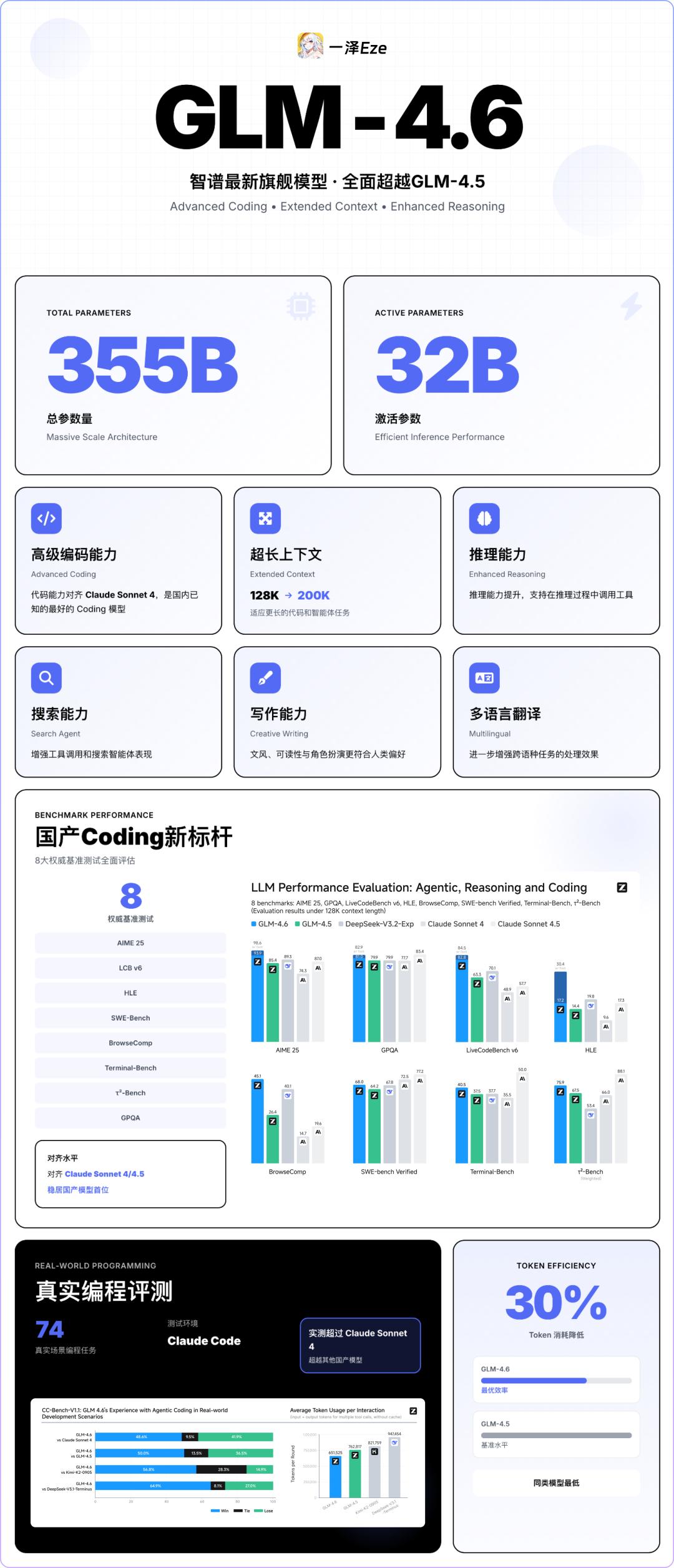
Key Upgrades:
- Coding Capability Upgrade: In real environments like Claude Code, GLM-4.6’s actual performance surpasses previous versions, matching Claude Sonnet 4.
- Increased Context Length: From 128K to 200K, allowing for more complex project code analysis in a single instance (DeepSeek V3.2 remains at 128K).
- Reduced Token Consumption: Compared to previous generations, it saves over 30% on token consumption for similar tasks, enabling faster work at lower costs.
GLM-4.6: Real Coding Scenario Evaluation
With every new model release, users are concerned about relative conclusions:
- How does the new model rank globally/domestically for target tasks?
- Is there a necessity to migrate from the current model?
The following compares GLM-4.6 with the latest Claude Sonnet 4.5, GPT-5 Codex, DeepSeek V3.2, and the still-excellent Gemini 2.5 Pro and Claude Sonnet 4, providing real comparisons and conclusions.
1) Classic Literacy Test: Generating Long Papers
Familiar readers know my classic benchmark:
Let the model read a long text, extract key content, and summarize it into a visual webpage.
This classic task design tests the model’s long-context performance, reasoning ability, and front-end coding quality and design aesthetics.
The model’s performance is improving rapidly, and this time the task difficulty was increased, challenging AI to summarize a paper into a visual HTML.
I tested using OpenAI’s recently released paper: “How people are using ChatGPT.”
The PDF is 64 pages long and 9.3 MB, requiring a substantial amount of content analysis.
Here are two different comparison results: one against the latest models and another against previous versions and itself:
GLM-4.6 vs. New Models: DeepSeek V3.2, Claude Sonnet 4.5, GPT-5 Codex
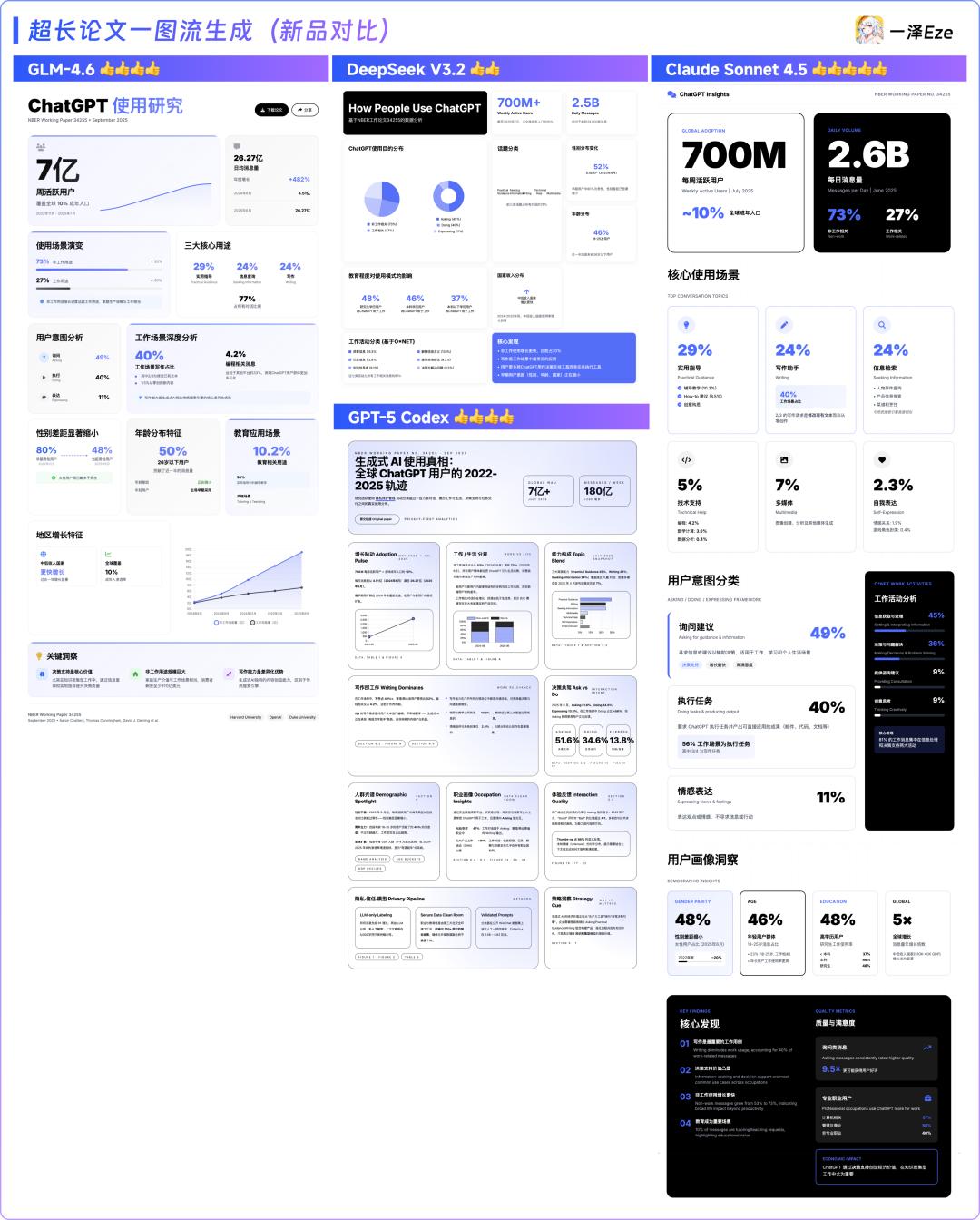
- GLM-4.6: The output layout is quite reasonable with good content richness.
- DeepSeek V3.2: Some graphical blanks appeared, with a monotonous layout design and lack of emphasis.
- GPT-5 Codex: Offers richer and deeper text presentation, resembling a complete report; however, it has minor layout overflow issues.
- Claude Sonnet 4.5: Most advantageous in layout structure and autonomous design sense, with appropriate detail (though it had a data hallucination issue that was acceptable).
New Model Ranking: Claude Sonnet 4.5 > GPT-5 Codex ≈ GLM-4.6 > DeepSeek V3.2
GLM-4.6 vs. Previous Models: GLM-4.5, Claude Sonnet 4, Gemini 2.5 Pro, Qwen3-Max
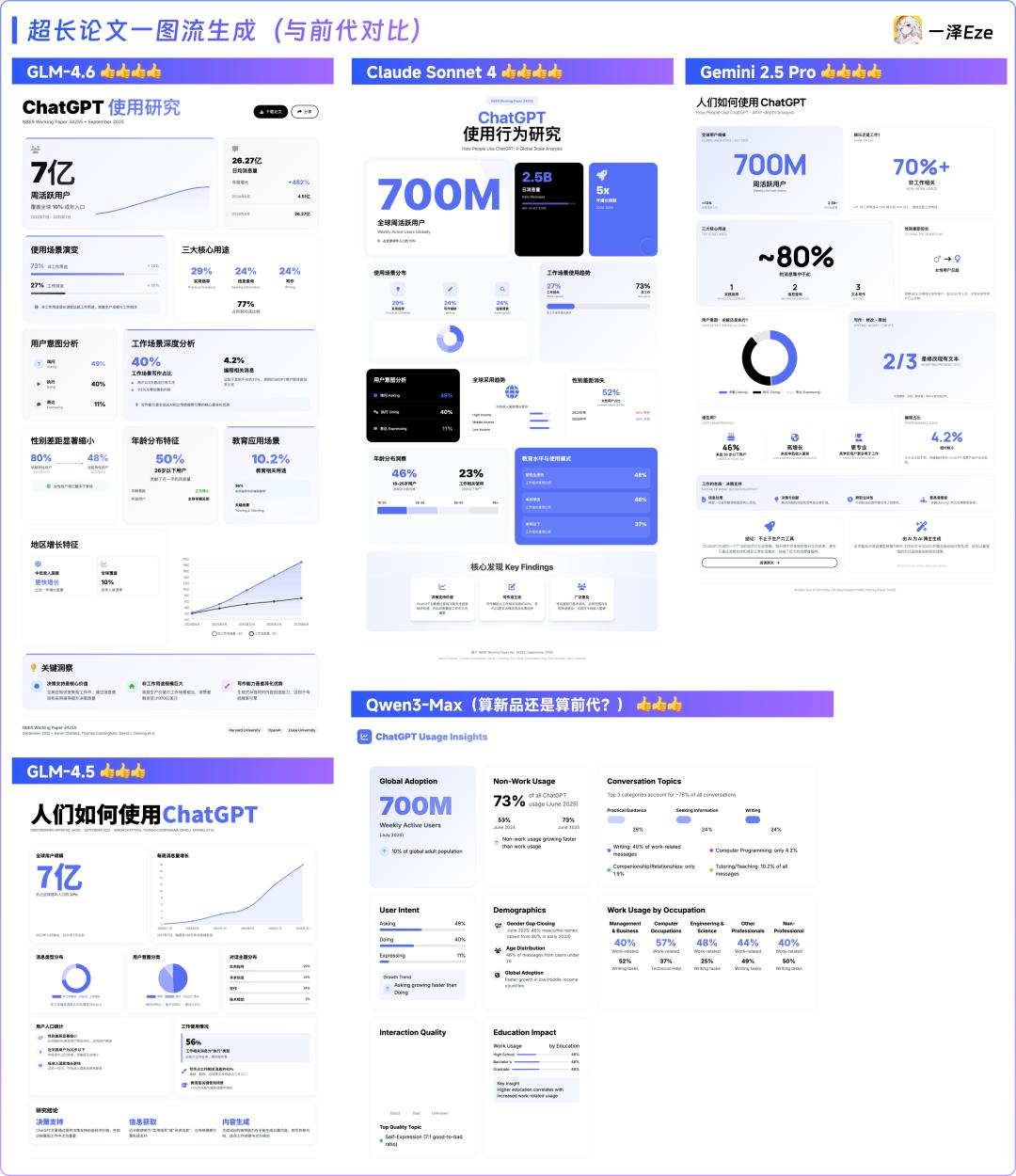
- Compared to the previous version 4.5, GLM-4.6 shows significant improvements in layout design and reasoning understanding (from content structure and extraction perspective), nearly on par with Claude Sonnet 4. I feel GLM-4.6 might be slightly better.
- Gemini 2.5 Pro: Thanks to its unique structured thinking chain, it has distinct advantages in content extraction, making it easier to read. However, its front-end design is slightly inferior to GLM.
- Qwen3: Recently updated to a Max version, rich in content but still has issues with language consistency, preferring to output English under Chinese prompts, and while the overall layout has no bugs, the design presentation is poor.
Previous Comparison Results: GLM-4.6 > Gemini 2.5 Pro ≈ Claude Sonnet 4 > GLM-4.5 ≈ Qwen3-Max
Overall, it’s evident that this wave of coding models released at the end of September shows significant improvements in reasoning, context attention, programming stability, and front-end aesthetics.
Test Conclusion
GLM-4.6 did not completely hold its ground but performed exceptionally well. Against Claude 4.5, the latest global top model, GLM-4.6 indeed falls slightly short in design and long text comprehension. However, it has solidified its status as a top-tier domestic coding model, showing clear progress compared to itself and previous domestic models, even holding its own against GPT-5 Codex in certain aspects.
Considering its high cost-performance ratio, GLM-4.6 continues to excel within its pricing range in the first round of testing.
2) Vertical Business Scenario Test: Designing a Data Dashboard Using Statistical Data
Continuing to raise the difficulty of coding tasks:
I had AI conduct deep research on 24 years of National Day tourism data and provided the report to AI, asking it to design a static data dashboard based on the data details.
Task Prompt:
Please design and develop a “2024 National Day Golden Week Tourism Data Smart Dashboard” for decision-makers in the tourism industry. The final product needs to include all code in a single HTML file that can be opened and run directly in a browser. Decision-makers need to quickly and intuitively understand the overall tourism market during the 2024 National Day holiday, grasp core highlights, and discover potential trends.
Requirements:
- Visual: Very professional, extremely beautiful, overview on one screen.
- Information: High information density, key indicators clear at a glance, complemented by rich visual charts.
- Dynamic and Interactive: Dynamic effects during data loading, responsive to user operations.
- Others: Do not reference external components to prevent loading/display issues.
Core Data:
- [2024 National Day Golden Week In-depth Insight Report], [Table 1: National Overall Tourism Data for the 2024 National Day Holiday], [Table 2: Transportation Data for the 2024 National Day Holiday], [Table 3: Tourism Data for Certain Provinces during the 2024 National Day Holiday], [Table 4: Cultural and Tourism Consumption and Activity Data for the 2024 National Day Holiday], [Table 5: Inbound and Outbound Tourism Data for the 2024 National Day Holiday], [Table 6: Visitor Profile Data for the 2024 National Day Holiday]
In this round, I compared GLM-4.6 with Claude Sonnet 4.5, GLM-4.5, Claude Sonnet 4, DeepSeek V3.2, and Gemini 2.5 Pro.
Without any design style prompt guidance, the front-end outputs generated by each model after one round of tasks and one round of optimization are shown below:
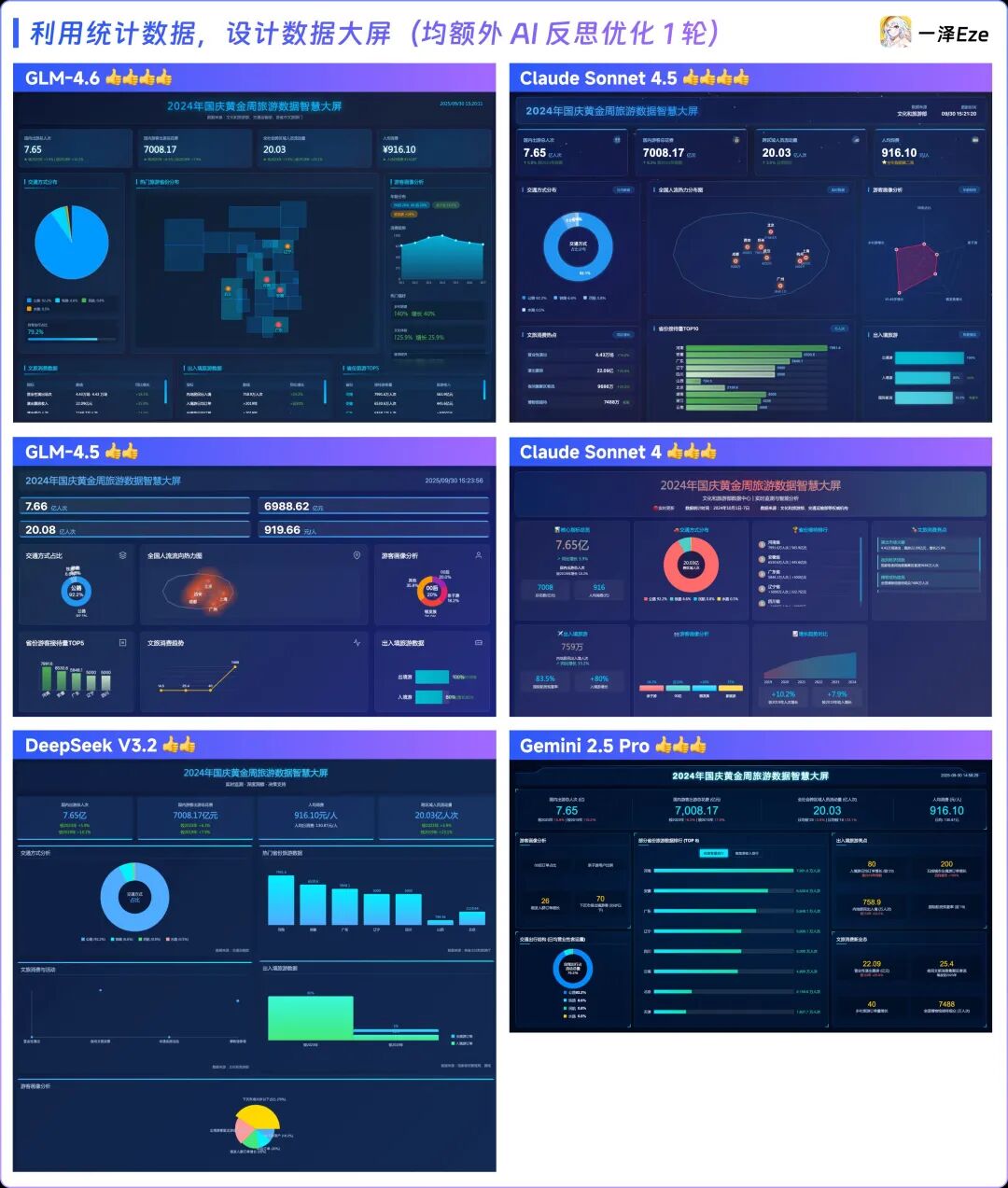
The results were surprising, with the ranking for this round of testing being:
- First Tier: GLM-4.6 ≈ Claude Sonnet 4.5
- Second Tier: Claude Sonnet 4 ≈ Gemini 2.5 Pro
- Third Tier: GLM-4.5 ≈ DeepSeek V3.2
This outcome exceeded my expectations; I initially thought this would be Claude 4.5’s domain, but GLM-4.6 delivered a pleasant surprise: without any additional prompt guidance, GLM-4.6 achieved results comparable to Claude’s new model Sonnet 4.5, showing significant progress compared to DeepSeek V3.2 and other previous models, including Claude 4. This data dashboard is crucial for To B software’s commercialization. Given GLM-4.6’s performance in this round, it represents a significant efficiency improvement for the domestic To B software industry.
It’s no wonder that my friend #赛博禅心 @大聪明 recently released a public account layout agent that also chose GLM-4.6 as its automatic layout foundation model.

Pricing Strategy: Comprehensive Upgrade of Coding Plan
After discussing performance, let’s talk about something more practical—pricing.
Claude has always been strong, but its high billing prices (around $3/M input tokens) and the $100-$200 packages, which often lead to account bans for domestic users, have made it difficult for many developers to commit to paying.
With the release of GLM-4.6, in addition to the regular pay-as-you-go pricing as follows:
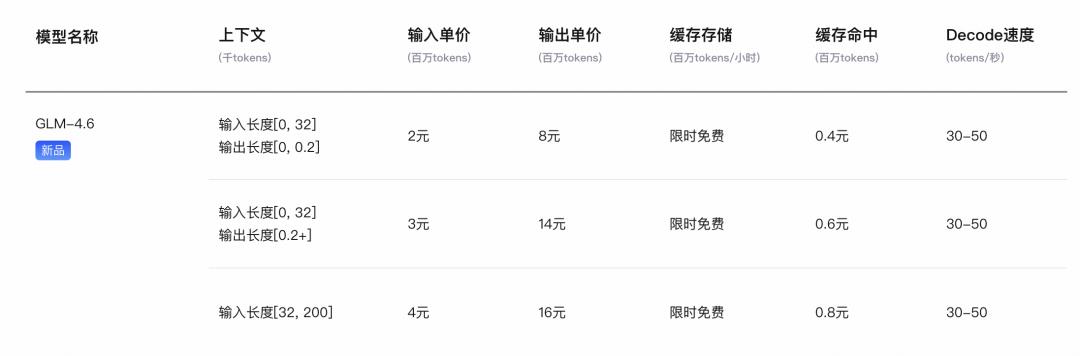
Zhizhu has also automatically upgraded the GLM Coding Plan subscription launched during the GLM-4.5 period:

- Model Upgrade: Existing subscribers are automatically upgraded to GLM-4.6.
- Capability Expansion: New image recognition and search capabilities.
- Pricing: As low as ¥20/month, with Lite/Pro/Max plans offering 120/600/2400 prompts every 5 hours, with total monthly usage reaching tens to hundreds of billions of tokens (approximately 0.1 times the API price).
- Platform Compatibility: Supports Claude Code, Roo Code, Kilo Code, Cline, and more than 10 programming tools.
Based on previous test results, you might consider GLM-4.6 as…
A model that only costs 1/7 of Claude’s price while providing a development experience that surpasses the recently released DeepSeek-V3.2, matching Claude Sonnet 4, and in some scenarios, even rivaling Claude 4.5?
In summary, the data does not lie:
Since the GLM-4.5 Coding Plan was opened, Zhizhu’s MaaS open platform API commercialization has achieved over tenfold growth.
Developers have already voted with real money.
Where to Try GLM-4.6?
- C-end Dialogue: z.ai, Zhizhu Qingyan fully supports GLM-4.6.
- API Usage: Domestic users can access it via bigmodel.cn, while overseas users can use z.ai.
- Open Source Deployment: GLM-4.6 will be released on Hugging Face and ModelScope.
- GLM Coding Plan Purchase: Available directly through bigmodel.cn, supporting both personal and corporate packages.
Conclusion: GLM-4.6, The Best Domestic Coding Model
As I conclude this intensive testing of GLM-4.6, I never anticipated such a flurry of model releases just two days before the National Day holiday (I was about to go on vacation…).
On one hand, there’s DeepSeek V3.2, which has reduced invocation costs by 50%, and on the other, Anthropic has released the Claude Sonnet 4.5 model, once again raising the ceiling of AI coding capabilities.
In this wave of model iterations at the end of September, looking back at GLM-4.6: In the classic long-text visual test, GLM-4.6’s overall performance surpassed the new DeepSeek V3.2 and other domestic models, matching Claude 4, and even being competitive with GPT-5 Codex.
In the close-to-commercial development scenario of the data dashboard test, GLM-4.6 also performed comparably to Claude 4.5 and showed significant improvement over previous models.
These test results make the final conclusion clear:
Combining performance with the increasingly valuable GLM Coding Plan, GLM-4.6 retains its title as the “best domestic coding model.”
GLM-4.6 may not yet match the “ceiling” level of Claude 4.5 in every dimension, but it offers a compelling price point, providing a coding model that is “good enough” in most scenarios and often surprising.
As always, if you have coding or agent task needs and care about “ease of use” and “affordability,” GLM-4.6 is absolutely worth your time to try out.
I also look forward to your testing reactions and feedback.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.