Introduction
DeepSeek today announced the launch of its flagship model, DeepSeek-V4-Pro with 1.6 trillion parameters, and the efficient model DeepSeek-V4-Flash with 284 billion parameters. Led by the Zhiyuan Research Institute, the Zhizhi FlagOS has quickly adapted both models for full deployment across more than eight AI chips, including Haiguang, Muxi, Huawei Ascend, Moore Threads (FP8), Kunlun Core, Pingtouge Zhenwu, Tianshu, and NVIDIA (FP8). FlagOS is also advancing the migration adaptation of the DeepSeek-V4-Pro model across multiple chips, with open-source plans to follow.
DeepSeek-V4-Flash Model Overview
The DeepSeek-V4-Flash, one of the two major models in the V4 series, employs a mixture of experts (MoE) architecture with a total parameter count of 284 billion and only 13 billion active parameters, supporting a context length of 1 million tokens. This model introduces a mixed attention mechanism (combining compressed sparse attention CSA and highly compressed attention HCA for improved long-context efficiency), manifold-constrained hyperconnections (mHC for enhanced cross-layer signal stability), and the Muon optimizer (to accelerate convergence and improve training stability).
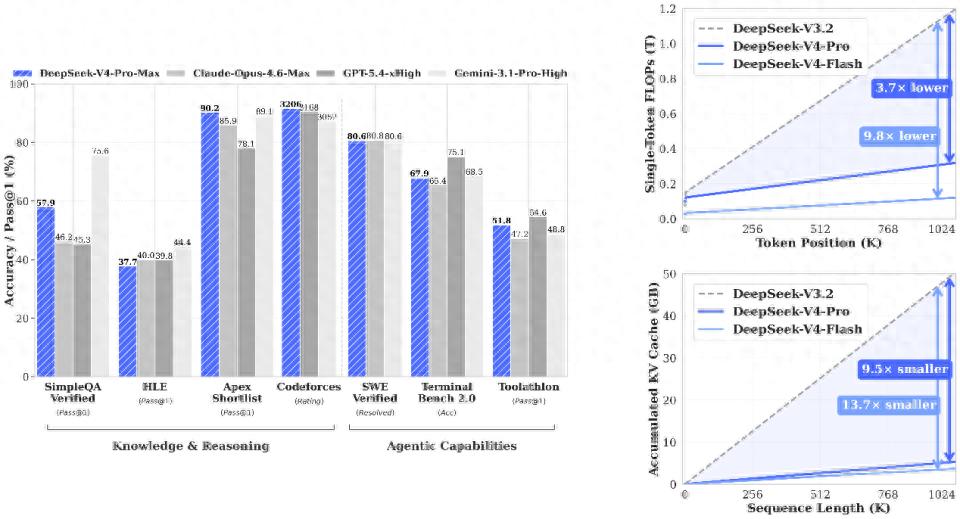
Pre-training data exceeds 32 trillion tokens, and the training adopts a two-phase paradigm—first, independent cultivation of domain experts through SFT and GRPO reinforcement learning, followed by online policy distillation to unify multi-domain capabilities into a single model. In the maximum inference mode (Flash-Max), the model’s inference capability approaches that of the Pro version, although it slightly lags behind in purely knowledge-based tasks and the most complex agent workflows due to parameter scale. The overall performance is referenced in the official evaluation results:
Key Technical Breakthroughs
The adaptation of DeepSeek-V4-Flash across multiple chips has led to breakthroughs in three key technologies within the FlagOS system software stack:
- FlagGems Full Operator Replacement: Achieving unified adaptation across multiple chips.
- Independent Tensor Parallel Strategy for o-group: Unlocking more low-memory scenarios.
- Native Weight Conversion from FP4+FP8 to BF16: Establishing precision pathways for mainstream chips.
Currently, no domestic AI chips support FP4, and NVIDIA only supports FP4 in high-end chips from Blackwell onwards. These three key technologies enable DeepSeek-V4 to run stably on various mainstream AI chips rather than being limited to a few high-end AI accelerator cards that support FP4 and large memory.
Breakthrough One: FlagGems Full Operator Replacement
The adaptation of DeepSeek-V4-Flash by FlagGems has replaced all operators in the model inference chain. What does this mean?
- Complete Independence from CUDA Operators: All core computational modules of DeepSeek-V4-Flash, including MoE expert scheduling, attention computation, RMSNorm, and TopK routing, have been re-implemented by FlagGems using Triton/Triton-TLE language, without calling any NVIDIA proprietary libraries like cuDNN/cuBLAS.
- No Need for Chip Manufacturers to Adapt Individually: Traditionally, each new model requires chip manufacturers to invest engineering teams for operator adaptation. Now, through the combination of FlagGems and the FlagTree compiler, new model operators can be directly compiled to multiple chip backends without any extra work from chip manufacturers.
- New Operators Available Immediately: The new computational modes introduced in DeepSeek-V4-Flash (such as the o-group related grouping routing mechanism) have corresponding new operators implemented by FlagGems, which are compiled uniformly to all supported chip backends via the FlagTree compiler.
FlagGems, the world’s largest Triton single operator library, now has over 400 commonly used operators for large models and has officially entered the PyTorch Foundation’s ecosystem collaboration project, achieving 90%-100% coverage of inference task operators across 40 mainstream models, fully supporting all computational needs of DeepSeek-V4-Flash.
Breakthrough Two: Independent Parallel Strategy for o-group
To further reduce computational overhead, DeepSeek-V4-Flash employs grouped output projection technology (Grouped Output Projection) configured for o-group=8, which traditionally limits tensor parallelism to a maximum of eight splits. Given that some mainstream domestic chips have single-card memory of 32GB or 64GB, especially in BF16 format, tensor parallelism must exceed eight splits to fit.
To overcome this limitation, FlagOS has designed and implemented a dedicated tensor parallel strategy for o-groups, ensuring that while o-groups are split into no more than eight parts, other model components can still adopt classic tensor parallel strategies and achieve splits greater than eight. Through different combinations of tensor parallel strategies, tensor parallel operation across more than eight devices can be realized.
FlagOS team’s modifications for o-group tensor parallelism include:
- Independent Parallel Strategy: Constructing a separate tensor parallel communication group for o-group, independent of existing tensor parallel communication groups, ensuring that while other model structures can split tensor parallelism beyond eight, o-group’s tensor parallelism remains within eight.
- Parameter Conversion Adjustments: Parameters related to o-group have been separately processed for tensor parallel splitting to ensure correct loading under the new independent tensor parallel strategy.
- Coverage Expansion: This optimization expands the operational chip range of DeepSeek-V4-Flash under a solely adopted tensor parallel strategy from “only a few high-end cards with 80GB or more memory” to “more mainstream domestic chips with multi-machine 64GB/32GB,” including major product lines from Haiguang, Muxi, Tianshu Zhixin, and others.
Breakthrough Three: Precision Conversion from FP4+FP8 to BF16
The DeepSeek-V4-Flash model is the first to adopt mixed precision of FP4+FP8, which is only supported on NVIDIA’s latest hardware from Blackwell onwards. Currently, all domestic non-NVIDIA AI chips do not support FP4, with only Moore Threads natively supporting FP8, while others mainly use BF16.
FlagOS has completed the full precision conversion from FP4 to BF16:
- Weight Re-quantization: Converting FP4 quantized weights to BF16 format, which requires inverse quantization calculations based on DeepSeek’s quantization scheme to ensure numerical precision.
- Rebuilding Computational Pathways: FP4 and BF16 have essential differences in underlying computation—FP4 has a narrower dynamic range, and accumulation precision and overflow handling strategies differ. FlagOS has adapted the BF16 pathways for key computational nodes in the inference chain, including GEMM, Attention, and MoE routing.
- Precision Alignment Verification: Verified against standard evaluation sets, the BF16 version maintains alignment with the core capability metrics of the original FP4 version, ensuring that the precision conversion does not introduce business-level performance losses.
This time, FlagOS has launched both FP8 and BF16 adapted versions, allowing DeepSeek-V4-Flash to run not only on the latest NVIDIA cards but also to be genuinely deployable on mainstream domestic chips in the FP8 and BF16 ecosystem.
FlagGems Open Source High-Performance New Operators
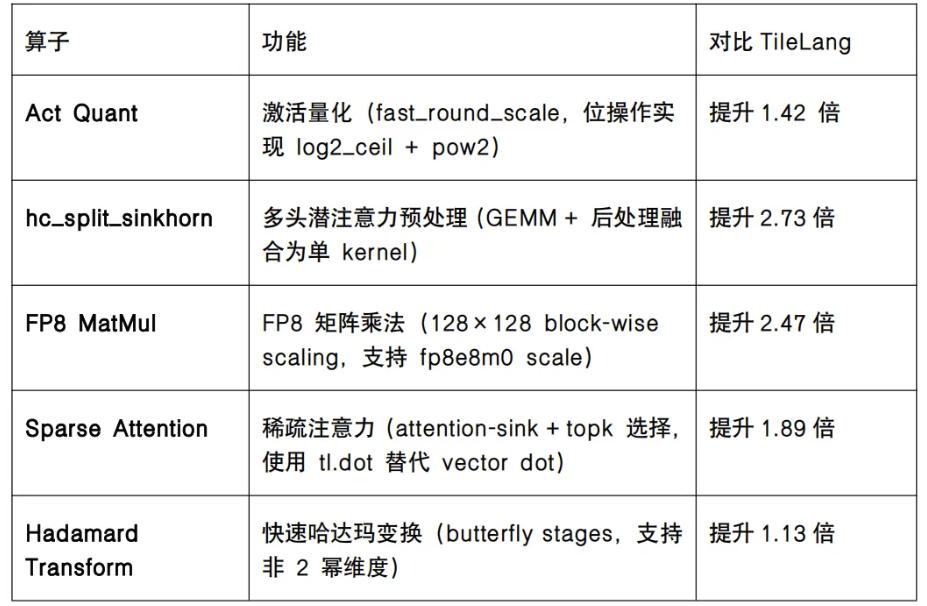
The newly released DeepSeek-V4-Flash includes approximately 67 operators, all fully supported by FlagGems. New operators such as Act Quant, hc_split_sinkhorn, FP8 MatMul, Sparse Attention, and Hadamard Transform have been introduced, achieving comprehensive support for DeepSeek-V4-Flash and laying an important foundation for cross-chip adaptation.
Performance Comparison of New Operators Supported by FlagGems
To support more AI chips, FlagOS has re-implemented the new operators used in DeepSeek-V4-Flash using Triton language, with performance exceeding native performance based on the FlagTree unified compiler.
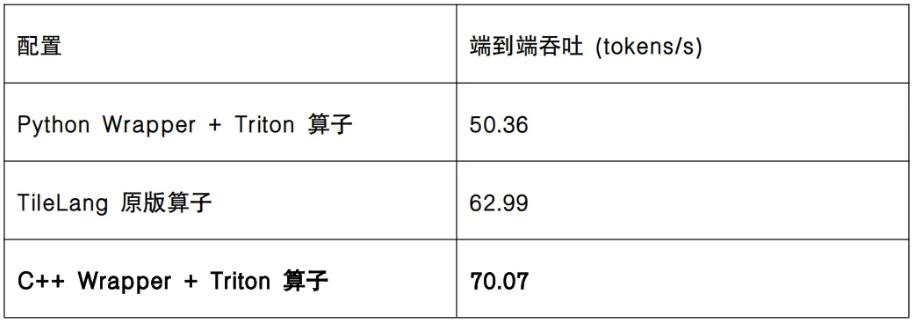
C++ Wrapper technology has been specifically developed by the FlagOS technical community to enhance the efficiency of operator kernel calls based on Triton language. Chips that currently support this technology include Huawei Ascend, Cambrian, Moore Threads, Pingtouge Zhenwu, and NVIDIA. Using C++ Wrapper technology, the end-to-end efficiency of models using Triton operators can be significantly improved under ordinary Transformers frameworks, achieving dual goals of cross-chip universality and efficient inference. Through end-to-end effect evaluations (NV H20, DeepSeek-V4-Flash FP8), C++ Wrapper + Triton is 11% faster than TileLang and 39% faster than the Python Wrapper version.
Developer Experience: “Multi-Chip at Release” + “Simplified Deployment”
-
Core Capabilities Aligned with Native Versions Verified by authoritative evaluation sets such as GPQA_Diamond and AIME, the FlagOS-adapted DeepSeek-V4-Flash aligns with the core capabilities of the CUDA native version in language understanding, complex reasoning, code generation, and mathematical computation, making it suitable for applications in finance, education, government services, and code development without concerns about performance degradation due to adaptation.
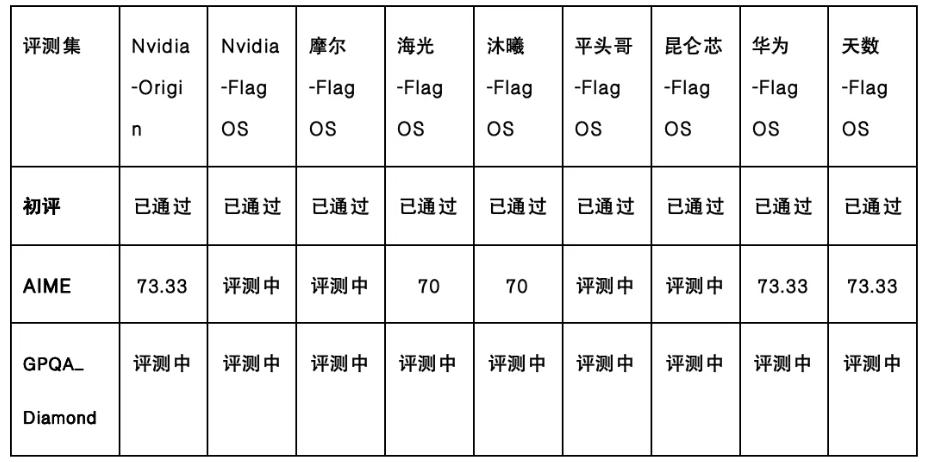
Note: This test result is only for mutual alignment verification between the pre-migration (Nvidia-Origin) and post-migration (-FlagOS) versions and does not represent the official performance of the DeepSeek model, which is based on data published by DeepSeek.
-
Simplified Deployment: Ready to Use with Seamless Optimization FlagOS has integrated core operator libraries, compilers, and other technical components into the DeepSeek-V4-Flash code framework, ensuring that when developers load the model, the underlying optimization code activates automatically without manual addition of any FlagOS initialization code. Additionally, a multi-chip version of the DeepSeek-V4-Flash-FlagOS model is directly provided based on FlagRelease, with standardized Docker images and one-click acceleration commands, addressing developers’ most pressing issues of environment configuration, effect alignment, and performance optimization.
FlagOS 2.0 Technology Base: Full-Stack Upgrade from Large Models to Intelligent Agents
The three breakthroughs of DeepSeek-V4-Flash rely on the full-link capability of the FlagOS 2.0 unified multi-chip system software stack. From the operator layer, compilation layer, framework layer to the tool layer, the entire link provides technical support for large model cross-chip adaptation, reducing the adaptation cycle from several weeks to several days, truly achieving rapid deployment.
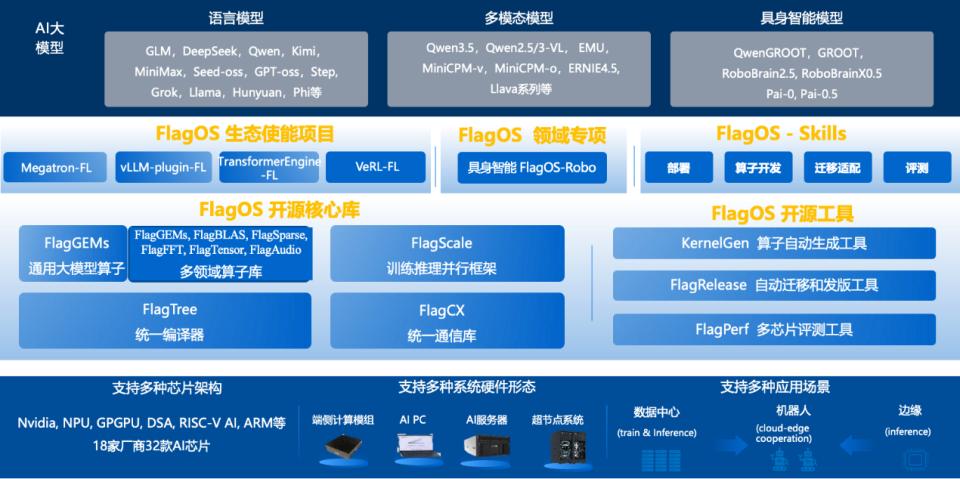
FlagOS: A System Software Stack for Various AI Chips
-
High-Performance Operator Library FlagGems: Deep adaptation of core operators to unleash hardware computing power. FlagGems, as the core high-performance universal large model operator library of FlagOS, is implemented based on Triton language, deeply adapting and optimizing core operators in the DeepSeek-V4-Flash inference chain, including MoE expert scheduling, attention computation, RMSNorm, and more, natively supporting nearly 20 AI chips including NVIDIA, Moore Threads, Muxi, Qingwei Intelligence, Tianshu, and others.
-
Unified AI Compiler FlagTree: Write once, compile for multiple chips. FlagTree is a unified compiler for multiple AI chip backends, deeply customized based on Triton, capable of compiling core operators of DeepSeek-V4-Flash into instructions recognizable by more than a dozen different AI chip backends, thoroughly solving the fragmentation issue of different chip compiler ecosystems and significantly reducing the development costs of cross-chip operator adaptation.
-
Model Cross-Chip Migration Release Tool FlagRelease: Semi-automatically achieving model cross-chip migration and version release. Leveraging FlagOS’s full-stack technical capabilities, FlagRelease has completed model migration, precision alignment, and version release for DeepSeek-V4-Flash across various chips, covering open-source community platforms such as HuggingFace and Modu. Developers can directly download and use it without self-migration. As of this article’s publication, FlagRelease has released cross-chip adaptation versions covering over 10 chip manufacturers, 12 hardware types, and more than 70 open-source model instances.
-
Unified Multi-Chip Access Plugin vLLM-plugin-FL: Seamless compatibility with native usage habits. vLLM-plugin-FL is a dedicated plugin created by FlagOS for the vLLM inference service framework, developed based on FlagOS’s unified multi-chip backend. It achieves multi-chip inference deployment without changing the original interface and user habits of vLLM. Currently, vLLM-plugin-FL supports multiple chips from NVIDIA, Moore Threads, Haiguang, Muxi, Pingtouge Zhenwu, Tianshu Zhixin, Kunlun Core, Huawei, and others.
Open Source Co-Creation: FlagOS Continues to Be the “Cross-Chip Adaptation Backbone” for Developers
Currently, “heterogeneous computing collaboration and large model accessibility” has become a core focus of the global open-source developer community. Breaking down hardware ecosystem isolation and enabling large models to run efficiently and cost-effectively on different computing platforms is a core demand of countless developers. From its inception, FlagOS has embedded open-source and collaborative intelligence into its technical DNA, always centering on developers. Through a full-stack open-source unified system software stack, it reduces the complex “M×N” hardware adaptation problem to “M+N,” becoming the most reliable cross-chip adaptation backbone for every developer.
Currently, FlagOS has formed a complete open-source technology system, with all core components open-sourced on GitHub, along with dozens of the latest mainstream foundational large models, more than ten AI chip adaptation schemes, and best practices available for developers to freely access and deeply customize:
- Four Core Technology Libraries: FlagGems universal large model operator library, FlagTree unified AI compiler, FlagScale training and inference parallel framework, FlagCX unified communication library, covering operator development, compilation optimization, parallel computing, and cross-chip communication across the entire link;
- Three Open Source Tool Platforms: FlagRelease large model automatic migration and release platform, KernelGen operator automatic generation tool, FlagPerf multi-chip evaluation tool, providing a one-stop toolchain from model adaptation, performance evaluation to engineering implementation;
- Full-Scene Extension Ecosystem: Framework enhancement components such as vLLM-plugin-FL, Megatron-LM-FL, TransformerEngine-FL, and the FlagOS-Robo embodied intelligence toolkit, covering all scenes of large model training, inference, and application.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.